
如何在 A64FX 上『正确地』跑 STREAM
Published:
缘起
富士通的 A64FX 处理器自公开以来就以其 ARM many-core 架构、SVE 向量指令集、1024 GB/s 的大 HBM2 带宽吸引了大量的目光。三年前 Fugaku 登顶 TOP500 以及之后 Fugaku 成为四冠王更是让 A64FX 风头无两。虽然 Knights Landing 已经尝试过把大内存带宽下放到 many-core CPU, 但高达 1024 GB/s 的大内存带宽依旧是 A64FX 的主要卖点之一。2021年初,我们学院买了几台 HPE 的 A64FX 机器,我自然是第一时间就申请了试用。
试了一圈以后我发现坏了,STREAM triad 竟然只能跑到 600+ GB/s, 距离 1024 GB/s 差得有点远啊。幸运的是,这是一个我在 x86 上碰到过的老问题。Triad 的访问模式是 a[i] = b[i] + scalar * c[i], 编译器的优化不到位的时候,会先把 a[i] 的 cache line 读进来,新数据写到 cache line 以后再写回到主内存里去。这样一来,实际上只需要读二写一的操作就变成了读三写一,有四分之一的内存带宽被浪费了。在 x86 上,这个问题可以通过 non-temporal store 解决 [1]。既然如此,那我就继续在 A64FX 上用 non-temporal store 就好了嘛。查了一下,对应的 non-temporal load/store 指令在 SVE intrinsic 里面是 svldnt1_f64 和 svstnt1_f64 [2]. 换上以后一跑,坏了,还是只有 600+ GB/s.
百思不得其解,然后我开始搜资料,搜到了富士通官方发的一个 PPT [3]. 这里指出,A64FX 需要用 zfill 来告诉系统来避免将 a[] 数组先从内存读到缓存里。这里放一页 PPT 里的图:
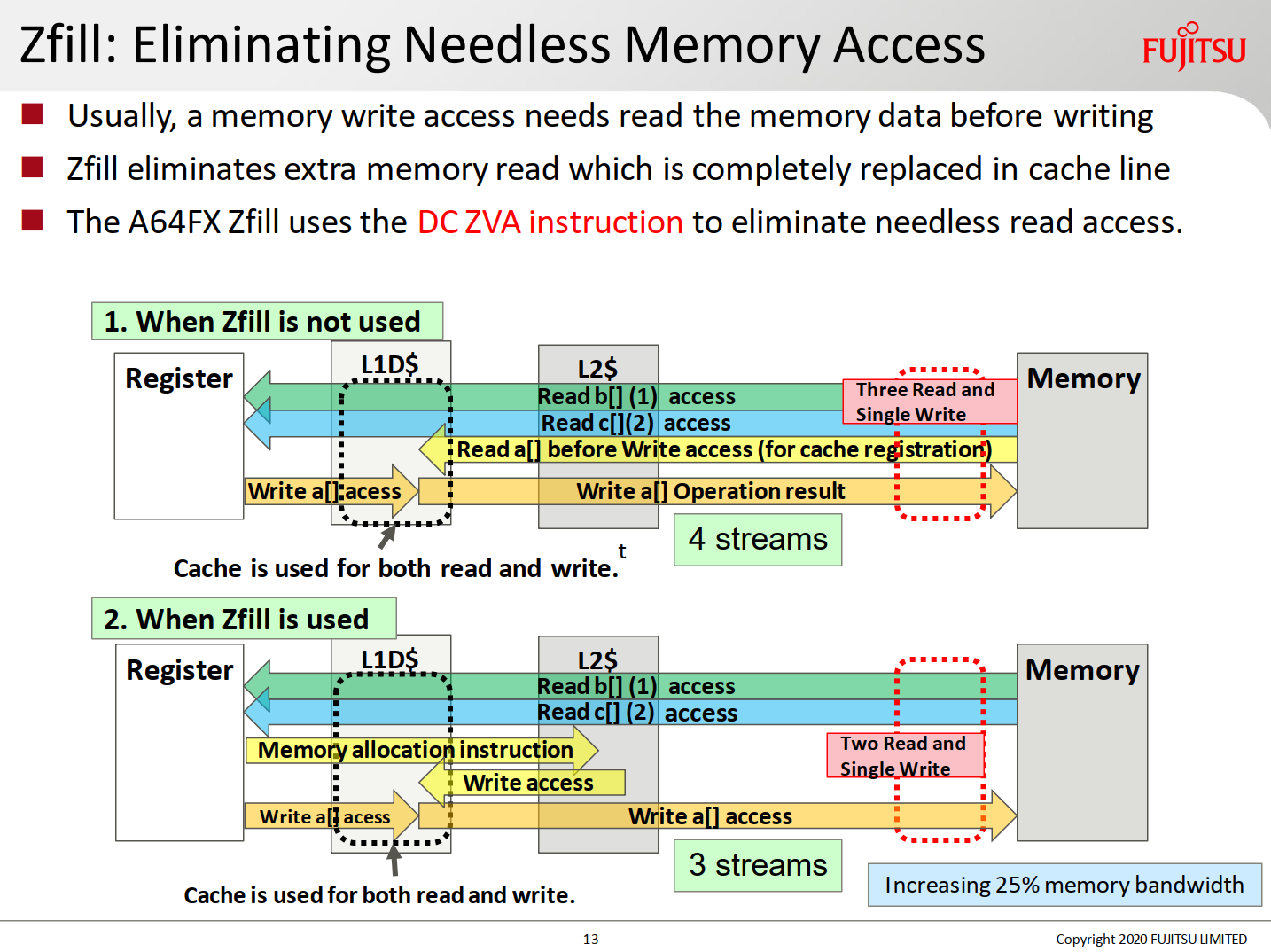
这张图告诉我们,zfill 是通过 dc zva 这条指令来完成的。那么这条指令如何使用呢?PPT 里没有说。不过 PPT 告诉我们,富士通的编译器专门加了一个 flag 叫 -Kassume=memory_bandwidth, 加上以后 triad 跑出来的带宽立马从 629 GB/s 飙升到 822 GB/s. 什么叫匠人精神啊,这就是匠人精神!(战术后仰)
当然,除了测内存带宽专用 flag 以外,富士通编译器还有其他的 flag 可以解决这个问题。比如 PPT 里,还给出了这么一组解决方案:-Kzfill=100 -Kprefetch_sequential=soft -Kprefetch_line=8 -Kprefetch_line_L2=16. 我猜这里 -Kzfill=100 是告诉编译器 100% 使用 zfill, 就像 ICC 里的 -qopt-zmm-usage=high 一样。后面其他的预取参数我就先不管了。
那么问题来了,这么好用的富士通编译器哪里有呢?
性空
没有富士通的编译器那就得自己想办法了。学校的机器既然是 HPE 的,那么自然附带了 Cray 的编译器。Cray 作为一个老牌超算厂商,我们来看看它的自动向量化表现。那么 Cray cc version 10.0.3 给出的答卷是多少分呢?630 GB/s. 好,抬出去,下一个。学校机器上还装过一个 ARM 自己的编译器套件,虽然现在可能因为试用期过了也没有了。知子莫若父,那么 ARM 自己的编译器能交出什么样的答卷呢?很遗憾,还是 600+ GB/s. GCC 呢?21年初的时候我自己编译了一个 GCC 10.2 试了一下,也是只有 620 GB/s 的水平。
自动向量化搞不定,那就只好自己动手写 intrinsic 了。好在富士通的 PPT 给了一个线索:dc zva. 同时,富士通也给出了一份 triad 的样例汇编代码 [4],使用了四路循环展开、预取指令和 dc zva。我照猫画虎写出了下面的 C code:
void triad_sve512_unroll4_st(const int n, const double scalar, double *a, const double *b, const double *c)
{
// a[0 : n0-1] are in an incomplete cache line
size_t a_addr = (size_t) a;
size_t a_addr_cl = (a_addr + 256 - 1) / 256 * 256;
int n0 = (a_addr_cl - a_addr) / sizeof(double);
// a[n0 : n1-1] are in complete cache lines
int ncl = sizeof(double) * (n - n0) / 256;
int n1 = n0 + ncl * 256 / sizeof(double);
// Handle the first part and the last part
#pragma omp simd
for (int i = 0; i < n0; i++) a[i] = b[i] + scalar * c[i];
#pragma omp simd
for (int i = n1; i < n; i++) a[i] = b[i] + scalar * c[i];
// Handle complete cache lines
a += n0; b += n0; c += n0;
svbool_t ptrue64b = svptrue_b64();
svfloat64_t vec_scalar = svdup_f64_z(ptrue64b, scalar);
for (int icl = 0; icl < ncl; icl++)
{
//asm("dc zva, %[a_ptr]\n" : : [a_ptr] "r" (a) : "memory");
svfloat64_t vec_b0 = svld1(ptrue64b, b + 8 * 0);
svfloat64_t vec_b1 = svld1(ptrue64b, b + 8 * 1);
svfloat64_t vec_b2 = svld1(ptrue64b, b + 8 * 2);
svfloat64_t vec_b3 = svld1(ptrue64b, b + 8 * 3);
svfloat64_t vec_c0 = svld1(ptrue64b, c + 8 * 0);
svfloat64_t vec_c1 = svld1(ptrue64b, c + 8 * 1);
svfloat64_t vec_c2 = svld1(ptrue64b, c + 8 * 2);
svfloat64_t vec_c3 = svld1(ptrue64b, c + 8 * 3);
svfloat64_t vec_a0 = svmad_f64_z(ptrue64b, vec_scalar, vec_c0, vec_b0);
svfloat64_t vec_a1 = svmad_f64_z(ptrue64b, vec_scalar, vec_c1, vec_b1);
svfloat64_t vec_a2 = svmad_f64_z(ptrue64b, vec_scalar, vec_c2, vec_b2);
svfloat64_t vec_a3 = svmad_f64_z(ptrue64b, vec_scalar, vec_c3, vec_b3);
svst1(ptrue64b, a + 8 * 0, vec_a0);
svst1(ptrue64b, a + 8 * 1, vec_a1);
svst1(ptrue64b, a + 8 * 2, vec_a2);
svst1(ptrue64b, a + 8 * 3, vec_a3);
a += 32; b += 32; c += 32;
}
}
这个代码是单线程 kernel, 需要在外面的多线程区域内调用。第 26 行被注释掉了,跑出来的速度是 630 GB/s. 一旦打开第 26 行,速度立即下降到了 286 GB/s. 说实话,我也不确定怎么用 dc zva 才是正确的。于是我给富士通的工程师发了一封邮件,对面热情地回复了我:
You need to write your C code so that your gcc -S output is the same as the GitHub code.
泪流满面,日本的匠人精神实在是太棒了!
此即诞生之刻
由于某些机缘巧合,我又重新捡起这个问题来看了。重新搜了一圈以后发现了一个 PPT [5]. 这个 PPT 仿照了一个 ARM 官方参考代码 [6] 里的的做法,为 zfill 加了一个 100 * 256 bytes 的提前量,其中 256 bytes 是 cache line size. 代码中的注释指出:
The zfill distance must be large enough to be ahead of the L2 prefetcher.
但是我查了一圈没有查到 L2 prefetcher 的预取距离有多大。我在自己的代码上面试了一下,发现最小只要提前 12 个 cache lines 进行预取就可以跑到 800-820 GB/s 左右的速度。